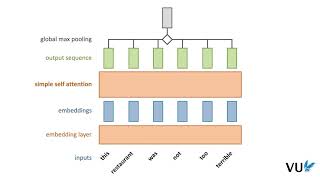
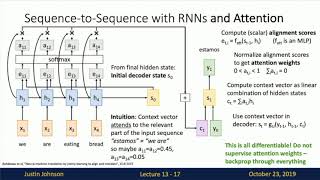
Media Summary: For more information about Stanford's online Artificial Intelligence programs visit: This lecture covers: 1. ERRATA: - In slide 23, the indices are incorrect. The index of the key and value should match (j) and theindex of the query should ... A complete explanation of all the layers of a
Linear Transformation In Self Attention Transformers In Deep Learning Part 3 - Detailed Analysis & Overview
For more information about Stanford's online Artificial Intelligence programs visit: This lecture covers: 1. ERRATA: - In slide 23, the indices are incorrect. The index of the key and value should match (j) and theindex of the query should ... A complete explanation of all the layers of a Breaking down how Large Language Models work, visualizing how data flows through. Instead of sponsored ad reads, these ...