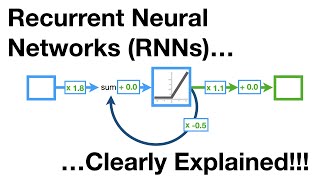
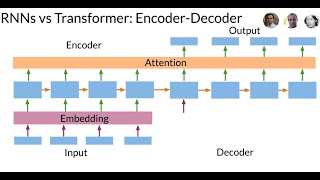
Media Summary: When you don't always have the same amount of data, like when translating different sentences from one language to another, ... For more information about Stanford's online Artificial Intelligence programs visit: This lecture covers: 1. Welcome to Deep Learning Talks. In this episode, we explore neural networks from the ground up, focusing on intuition rather ...
Linear Attention Explained From First Principles Transformers Rnns - Detailed Analysis & Overview
When you don't always have the same amount of data, like when translating different sentences from one language to another, ... For more information about Stanford's online Artificial Intelligence programs visit: This lecture covers: 1. Welcome to Deep Learning Talks. In this episode, we explore neural networks from the ground up, focusing on intuition rather ...