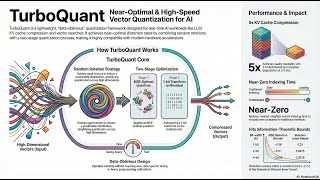
Media Summary: Is your AI too slow or using too much memory? Is the "Memory Wall" finally crumbling? In this video, we dive deep into ** Slow LLMs due to memory constraints? 🤯 TurboQuant is revolutionizing! We compress high-dimensional vectors while preserving ...
Turboquant Explained Online Vector Quantization With Near Optimal Distortion For Llms - Detailed Analysis & Overview
Is your AI too slow or using too much memory? Is the "Memory Wall" finally crumbling? In this video, we dive deep into ** Slow LLMs due to memory constraints? 🤯 TurboQuant is revolutionizing! We compress high-dimensional vectors while preserving ... This video provides an in-depth exploration of AI models are getting bigger every year, and memory is quickly becoming the biggest bottleneck. Larger models need more ...

![[Trending paper] TurboQuant Explained: Near-Optimal Online Vector Quantization #ml](https://i.ytimg.com/vi/UuZ_dhXb3w0/mqdefault.jpg)