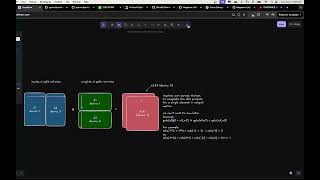
Media Summary: In this talk we present how we trained a 530B parameter Episode 83 of the Stanford MLSys Seminar Series! ML Performance Reading Group Session 8, where we covered the paper "
Efficient Large Scale Language Model Training On Gpu Clusters Using Megatron Lm - Detailed Analysis & Overview
In this talk we present how we trained a 530B parameter Episode 83 of the Stanford MLSys Seminar Series! ML Performance Reading Group Session 8, where we covered the paper " Let's talk about an intriguing topic today, diving into the world of After 6+ months in the making and burning over a year of Learn in-demand Machine Learning skills now → Learn about watsonx →