Media Summary: What if you could skip redundant LLM calls — and make your AI app faster, cheaper, and smarter? In this video, ... Stop overpaying for your LLM API calls! If you are building AI applications, you've likely noticed that costs scale quickly. Your LLM agents are slow and burning cash because they repeat the same expensive calls over and over. In this video, I show ...
Caching For Agentic Java Systems Internal Distributed And Semantic - Detailed Analysis & Overview
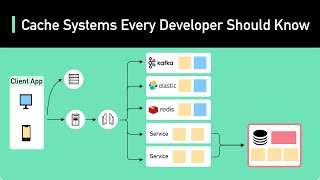
What if you could skip redundant LLM calls — and make your AI app faster, cheaper, and smarter? In this video, ... Stop overpaying for your LLM API calls! If you are building AI applications, you've likely noticed that costs scale quickly. Your LLM agents are slow and burning cash because they repeat the same expensive calls over and over. In this video, I show ... Your AI app is as fast as its database. But repeated queries in reasoning loops can turn milliseconds into seconds. The Remote ... In this deep dive, we'll explain how every modern Large Language Model, from LLaMA to GPT-4, uses the KV In this video, we dive into LMCache, an open-source KV
Feeling overwhelmed by high AI API costs and latency? In this video, we break it down into simple pieces. We teach you ... This is how to enhance the performance of intelligent applications by implementing