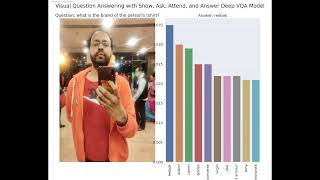
Media Summary: Authors: Pan Lu (Tsinghua University); Lei Ji (Microsoft); Wei Zhang (East China Normal University); Nan Duan (Microsoft); Ming ... ai The problem of answering questions about an image is popularly known as Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ...
A Tutorial On The Visual Question Answering Task - Detailed Analysis & Overview
Authors: Pan Lu (Tsinghua University); Lei Ji (Microsoft); Wei Zhang (East China Normal University); Nan Duan (Microsoft); Ming ... ai The problem of answering questions about an image is popularly known as Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... This small demo shows a Pal Robotics TIAGo++ robot executing a basic VISION AND TEXT TRANSFORMER FOR PREDICTING ANSWERABILITY \\ON