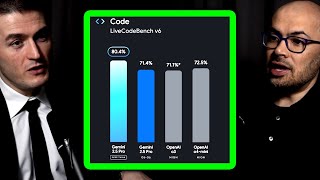
Media Summary: It may look like Gemini 3.1 Pro or Claude 4.6 Opus is t he best model, but there's something hiding beneath the surface. Why lines of code is a useless metric. Join the community ... ARC-AGI-3 from the ARC Prize measures intelligence by testing learning efficiency across 135 interactive visual games.
Why Ai Benchmarks Dont Matter Anymore - Detailed Analysis & Overview
It may look like Gemini 3.1 Pro or Claude 4.6 Opus is t he best model, but there's something hiding beneath the surface. Why lines of code is a useless metric. Join the community ... ARC-AGI-3 from the ARC Prize measures intelligence by testing learning efficiency across 135 interactive visual games. Lex Fridman Podcast full episode: Thank you for listening ❤ Check out our ... The world no longer runs on averages—it runs on power laws. In the age of An overview of the JS ecosystem in 2026 Join the community ...
Is a car that wins a Formula 1 race the best choice for your morning commute? Probably not. In this sponsored deep dive with ... In this mini clip of episode , we discuss why the future of







![Why High Benchmark Scores Don’t Mean Better AI [SPONSORED]](https://i.ytimg.com/vi/rqiC9a2z8Io/mqdefault.jpg)



