Media Summary: Ready to become a certified watsonx Generative Try Voice Writer - speak your thoughts and let In this deep dive, we'll explain how every modern Large Language Model, from LLaMA to GPT-4, uses the KV
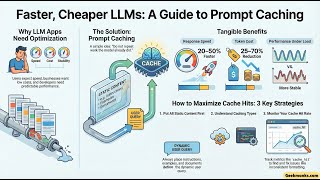
What Is Prompt Caching Optimize Llm Latency With Ai Transformers - Detailed Analysis & Overview
Ready to become a certified watsonx Generative Try Voice Writer - speak your thoughts and let In this deep dive, we'll explain how every modern Large Language Model, from LLaMA to GPT-4, uses the KV Connect with me ▭▭▭▭▭▭ LINKEDIN ▻ / trevspires TWITTER ▻ / trevspires In this 7-minute tutorial, discover how to ... In this engineering deep dive, we explore how Local inference capable LLMs are getting smarter and faster, but there's one critical capability that must work correctly to get the ...