Media Summary: Google Cloud Developer Advocate Nikita Namjoshi demonstrates how to get started with Google Cloud Developer Advocate Nikita Namjoshi introduces how The Mixture-of-Experts (MoE) is a sparsely activated deep
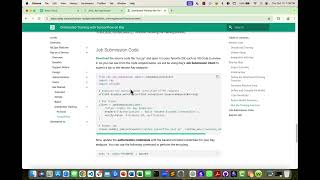
Mirroredstrategy Demo For Distributed Training - Detailed Analysis & Overview
Google Cloud Developer Advocate Nikita Namjoshi demonstrates how to get started with Google Cloud Developer Advocate Nikita Namjoshi introduces how The Mixture-of-Experts (MoE) is a sparsely activated deep For more information about Stanford's online Artificial Intelligence programs visit: To learn more about ... The tf.distribute.Strategy API provides an abstraction for distributing your A complete tutorial on how to train a model on multiple GPUs or multiple servers. I first describe the difference between Data ...
Learn about a new tf.distribute strategy, ParameterServerStrategy, which enables asynchronous